

Secure URL algorithms ensure that URLs used for sensitive information, authentication, or secure access are both encrypted and verified. These algorithms protect against unauthorized data access by encoding information in URLs and providing a means to verify its authenticity.
HMAC-SHA (Hash-Based Message Authentication Code with SHA)

Description:
HMAC-SHA is a cryptographic mechanism that combines a secure hash function (such as SHA-1, SHA-256, or SHA-512) with a secret key to generate a unique message digest, often referred to as a signature. This signature ensures the authenticity and integrity of data transmitted via URLs. When used in URLs, the HMAC acts as a digital seal, guaranteeing that the URL has not been altered or tampered with during transmission.
HMAC-SHA does not encrypt the URL content but validates its authenticity, making it especially valuable for APIs, temporary access links, and other secure communication scenarios.
How It Works
Generate the HMAC:
- The server takes the original URL (or specific parameters within it) and a pre-shared secret key.
- Using a cryptographic hash function (like SHA-256), it generates an HMAC based on this combination.
- Append HMAC to URL:
- The resulting HMAC is appended to the URL as a query parameter (e.g., ?signature=<HMAC>).
Transmit the URL:
- The URL, along with the appended HMAC, is sent to the client or used as a secure link.
- Verification:
- When the client sends the URL back to the server or uses the link, the server extracts the HMAC.
- It recalculates the HMAC using the received URL and the secret key.
- If the newly calculated HMAC matches the one appended to the URL, the URL is verified as authentic and unaltered.
Pros:
High Security:
- Ensures both integrity and authenticity of the URL, preventing unauthorized tampering.
Fast and Efficient:
- HMAC generation and verification are computationally efficient, even for large-scale applications.
Widely Supported:
- Compatible with most programming languages and frameworks, making it easy to implement.
Tamper Prevention:
- Protects URLs from malicious alterations by unauthorized parties.
Deterministic:
- The same input will always generate the same HMAC, ensuring consistency in verification.
Cons:
- Relies on securely storing and sharing the secret key.
- Does not encrypt URL content (only validates it).
Use Case:
Commonly used in APIs and signed URLs for file-sharing services like AWS S3 or Google Cloud.
2. AES (Advanced Encryption Standard)
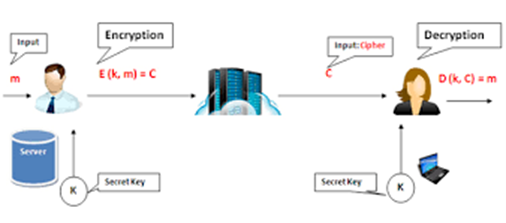
Description
AES (Advanced Encryption Standard) is a widely used symmetric encryption algorithm designed to securely encrypt and decrypt data. It ensures the confidentiality of sensitive information embedded in URLs, making it highly effective in safeguarding access tokens, user IDs, session identifiers, and other critical data transmitted over the web. Since it uses the same secret key for encryption and decryption, AES requires secure key exchange and management to prevent unauthorized access.
AES is recognized for its high performance, adaptability, and robustness. It supports key sizes of 128, 192, and 256 bits, allowing for flexible implementation based on the required security level.
How It Works
Encryption Process:
- Sensitive URL parameters, such as tokens or user identifiers, are encrypted on the server using AES and a pre-defined secret key.
- The encrypted data is converted into a Base64 or URL-safe string and appended to the URL, ensuring it remains compatible with HTTP transmission.
Decryption Process:
- When the URL is received by the server or a designated endpoint, the encrypted parameters are extracted.
- Using the same secret key, the encrypted data is decrypted, revealing the original information.
Transmission Security:
Along with HTTPS for secure communication, AES encryption adds an additional layer of protection to ensure that sensitive URL data remains confidential, even if intercepted.
Pros:
- Strong encryption ensures data confidentiality.
- Efficient and widely supported.
- Prevents unauthorized access to sensitive URL data.
Cons:
- Key exchange and management can be challenging.
- Requires additional processing power for encryption and decryption.
Use Case:
Encrypting sensitive data in URLs, such as access tokens, user IDs, or session identifiers.
3. RSA (Rivest-Shamir-Adleman)
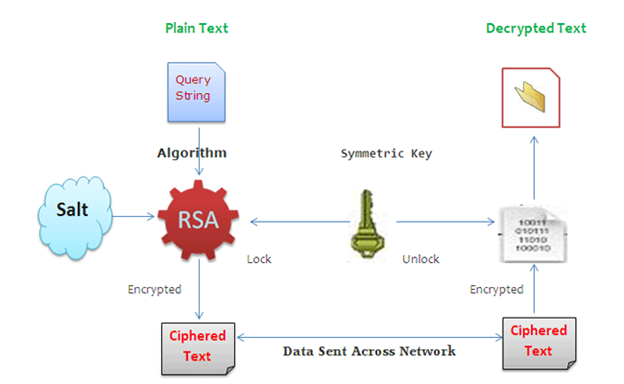
Description
RSA is a widely used asymmetric encryption algorithm designed for secure data transmission. It relies on a pair of cryptographic keys: a public key for encryption and a private key for decryption. Unlike symmetric encryption, RSA does not require both parties to share a single secret key, making it ideal for secure communications over public networks.
When used for securing URLs, RSA ensures that sensitive data can only be decrypted by the intended recipient, providing robust protection against unauthorized access.
How It Works
Key Generation:
- A pair of cryptographic keys (a public key and a private key) is generated.
- The public key is shared with the sender, while the private key remains securely with the recipient.
Encrypting URL Content:
- The server encrypts sensitive URL data using the recipient’s public key.
- The encrypted data is appended to the URL as a query parameter.
Transmitting the URL:
The encrypted URL is sent to the recipient over public or private channels.
Decrypting the URL:
- The recipient retrieves the encrypted data from the URL.
- Using their private key, the recipient decrypts the data to access the original content.
Pros:
Strong Encryption:
- RSA offers robust security, as only the private key can decrypt data encrypted with the corresponding public key.
No Shared Secret Key:
- There is no need to exchange or share a single key between parties, reducing the risk of key compromise.
Secure for Public Channels:
- Data encrypted with the public key can safely traverse insecure channels, as only the recipient can decrypt it.
Versatility:
- RSA can be used for both encryption and digital signatures, providing authenticity and integrity in addition to confidentiality.
Non-Repudiation:
- RSA’s use in digital signatures ensures that senders cannot deny having sent a message or URL.
Cons:
Slower Than Symmetric Algorithms:
· RSA is computationally intensive and slower compared to symmetric encryption algorithms like AES, especially for large amounts of data.
Use Case:
Sharing sensitive URLs in secure communications, such as email invitations or encrypted download links.
4. Base64 Encoding
Description
Base64 encoding is a technique used to encode binary data into a text format, making it suitable for transmission in URLs. Although not an encryption method, Base64 ensures URL-safe encoding by replacing non-printable characters with alphanumeric symbols. It is typically used for obfuscation rather than encryption.
How It Works
Encoding Data:
Sensitive URL parameters are encoded using Base64 to convert them into a URL-safe string.
Appending to URL:
The encoded string is appended as a query parameter.
Decoding:
The receiver decodes the string back to its original form.
Pros
- Simple and efficient.
- Compatible with all web frameworks.
- Avoids URL encoding issues.
Cons
- Not secure on its own as it does not encrypt or validate data.
- Vulnerable to decoding by anyone with basic tools.
Use Case
Obfuscating non-sensitive data in URLs for improved readability.
5. URL Tokenization
Description
Tokenization replaces sensitive information in URLs with unique, non-identifiable tokens. These tokens map to the original data stored securely on the server, reducing the risk of exposing sensitive details.
How It Works
Generate Token:
- The server generates a random token for the sensitive data.
Store Mapping:
- The token and its corresponding data are stored securely in a database.
Append to URL:
- The token replaces the sensitive data in the URL.
Token Validation:
- On URL access, the server retrieves the original data using the token.
Pros
- Ensures sensitive data is never exposed.
- Easy to revoke tokens if needed.
- Ideal for one-time or temporary URLs.
Cons
- Requires server-side storage for token mapping.
- Adds complexity to URL management.
Use Case
Temporary access URLs for password resets or file downloads.
6. SHA-3 Hashing
Description
SHA-3 is a secure cryptographic hashing algorithm that generates fixed-length digests. When used with URLs, it ensures data integrity by creating a hash that can detect any tampering.
How It Works
Generate Hash:
- Compute a SHA-3 hash of the URL or specific parameters.
Append to URL:
- Add the hash as a query parameter.
Verify Integrity:
- Recalculate the hash on the server and compare it with the received hash.
Pros
- Strong protection against tampering.
- Efficient and resistant to collision attacks.
Cons
- Does not encrypt data.
- Relies on HTTPS for confidentiality.
Use Case
Ensuring the integrity of signed URLs in APIs.
Conclusion
In an era where data privacy and security are paramount, securing web URLs has become an essential practice for protecting sensitive information and ensuring trusted communication over the web. Each algorithm discussed—HMAC-SHA, AES, RSA, and others—offers distinct strengths and is suited for different use cases.
- HMAC-SHA ensures authenticity and integrity, making it ideal for validating URLs and preventing tampering.
- AES provides robust encryption for securing sensitive data within URLs, ensuring confidentiality.
- RSA offers powerful asymmetric encryption for secure communication, especially over public channels.
- Additional algorithms, like Elliptic Curve Cryptography (ECC) and URL Tokenization, provide modern, efficient, and scalable solutions for specific use cases.
Selecting the right algorithm depends on the application’s requirements, including the need for encryption versus validation, computational efficiency, key management, and the type of data being transmitted. Combined with HTTPS and proper security practices, these algorithms form a strong foundation for protecting web URLs in today’s digital landscape.
References
- HMAC-SHA
- National Institute of Standards and Technology (NIST): HMAC Guidelines
- Wikipedia: HMAC Overview
- AES
- Federal Information Processing Standards (FIPS): AES Specification
- OpenSSL Documentation: AES Encryption
- RSA
- Rivest, Shamir, Adleman (1978): Original RSA Paper
- RSA Security: Understanding RSA
- Elliptic Curve Cryptography (ECC)
- Certicom Research: ECC Overview
- URL Tokenization
- Cloudflare Blog: Tokenized URLs
- AWS Documentation: Presigned URLs
- HTTPS and Secure Communication
- Mozilla Developer Network (MDN): HTTPS
- Let’s Encrypt: Securing Websites
- Quantum-Safe Encryption
- National Institute of Standards and Technology (NIST): Post-Quantum Cryptography
- IBM Research Blog: Quantum-Safe Cryptography
These resources provide comprehensive insights into each algorithm, guiding developers and security professionals in implementing secure web URL practices effectively.












